中國首個古籍大語言模型發佈:智能作詩、精確翻譯、自動標點…分享到:
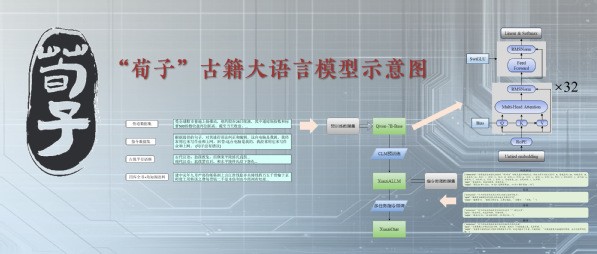
香港新聞網12月13日電 據南京農業大學網站消息,12月2日,該校信息管理科學系王東波教授研究團隊在北京發佈“荀子”古籍大語言模型。“荀子”古籍大語言模型是在國家社科基金重大項目“中國古代典籍跨語言知識庫構建及應用研究”的支持下,聯合中華書局古聯公司推出的專門進行古籍處理與研究的智能工具。該模型包含《四庫全書》在內的絕大多數傳世古籍文獻,擁有超過20億字的大型語料庫。
“荀子”古籍大語言模型以古籍智能化研究為目的,為古籍智能處理而設計,在推動中國古籍研究與保護工作創新發展、提高中華傳統文化傳承的效率與質量、實現大語言模型與古籍處理的深度融合上提供重要支撐。該模型作為開源公益研究成果已在GitHub、ModelScope等網站發佈,用戶可免費下載部署使用。 據介紹,王東波教授研究團隊在南京農業大學高算力基礎設施支持下,持續10年深耕古籍文獻數字化研究,同時依托中華書局提供的應用場景,在古籍開源大語言模型上實現AI人工智能垂直細分領域的全國首創。 該開源模型包括兩個部分:基座模型XunziALLM與對話模型XunziChat。 其模型亮點包括:智能標引,能夠對古籍中的內容進行高質量主題標引,幫助研究人員快速了解文章主題; 信息抽取,能夠自動從古籍中抽取關鍵信息,如人物、事件、地點等,大大節省了信息整理時間; 詩歌生成,能夠根據給定的主題或關鍵詞,自動生成符合語法規則和韻律要求的古詩,為詩詞愛好者提供創作靈感; 高質量翻譯,對於難以理解的古籍文獻,能夠進行精準的現代文翻譯,幫助研究人員更好地理解原文含義; 閱讀理解,能夠對給出的古文文本進行分析解釋,實現對古籍文本的自動閱讀; 詞法分析,可以完成古籍文本的自動分詞和詞性標註,有效提升研究效率; 自動標點,可以快速完成古籍文本的斷句和標點,提升使用者對古籍文本的閱讀體驗。 此外,同時發佈的基座模型,用戶也可以根據自己的需求,使用本地的訓練語料微調“荀子”基座模型,使其在古籍下遊處理任務上取得更優越的處理性能。(完) 【編輯:丘志彬】
|
視頻更 多
衝上雲霄飛躍理想 內地機師在香港圓航空夢
台前立委雷倩:賴清德實際上是色厲內荏 講話很大聲但底氣很不足
(直通巴黎)奧運開幕在即 巴黎準備好了嗎?
(直通巴黎)原來這就是“法式浪漫”!
廣東臍帶血跨境送港 5歲重型地貧病童將獲移植
(直通巴黎)探秘奧運會主媒體中心 記者收到神秘紀念品
(直通巴黎)直擊港乒備戰 隊員黃鎮廷:今屆沒上屆壓力大
來論更 多
評論更 多
論壇更 多閱讀排行 |