
繁体
简体
香港新聞網6月9日電 今年5月底,美國企業支出管理平台Ramp的首席經濟學家阿拉·卡拉齊安(Ara Kharazian)做了一個預判:美國企業管理AI支出會越來越精打細算,會更多嘗試開源模型,或者OpenAI、Anthropic和谷歌家更便宜的低配版本。6月3日,Ramp發佈6月AI軟件使用和付費趨勢榜,卻給出了一個令阿拉·卡拉齊安震驚的答案:登頂的是中國DeepSeek!

人們在中國浙江省杭州市文三數字生活街區的AI黑科技市集上體驗DeepSeek的人工智能大模型。新華社發(龍巍 攝)
誰料到美國公司會用DeepSeek?
據了解,美國企業支出管理平台Ramp公司負責替5萬多家美國企業管企業卡和對公賬單,每個月經手數十億美元的開支。它的軟件趨勢榜負責統計哪些軟件供應商正在被企業第一次付款,增速最快。這張榜單過去的常客是Figma、Fireworks AI這類矽穀自己人,一家中國AI公司登頂,是頭一回。
"我沒有料到美國公司會去用DeepSeek。"Ramp的首席經濟學家阿拉·卡拉齊安在報告裡寫道。
付款記錄裡還有一個更隱藏的細節。這些美國公司沒有走下載開源權重、本地部署模型的思路,而是直接向DeepSeek付費。
"說得明確一點:這不只是自部署的開源使用。企業在直接通過DeepSeek收發數據。"卡拉齊安特意強調了這一點。
卡拉齊安補充表示稱,這可能是迄今為止最明顯的信號,說明美國企業正在尋找OpenAI和Anthropic的低成本替代品,一些公司願意用更便宜的中國模型,"讓美國的數據在中國託管的服務器之間來回傳輸"。
這不是DeepSeek第一次出現在美國企業的賬本上。2025年1月,R1發佈引爆全球,DeepSeek的應用一度超過ChatGPT登頂美區App Store免費榜,在Ramp當時的數據榜單裡,美國企業對DeepSeek的採用率同期衝到0.3%,隨後很快回落到0.1%。
如果說2025年初更像是企業跟著輿論熱度的一次集體試用。那這一輪企業們又用回了DeepSeek的核心變化在於動機:AI賬單的財務壓力。

Ramp發佈的2026年6月軟件供應商趨勢榜,DeepSeek登上代表突破性增長的“Trending”榜首(紅框標注)。圖自Ramp官網數據截圖
Uber四個月燒光全年Token預算?
美國企業的AI賬單有多難看,已經不再是行業內才知道的秘密。
日前,美國咨詢公司貝恩調查了全球951家年收入超過1億美元的企業,結論相當不客氣:在企業AI累計支出突破1萬億美元之後,AI帶來的實際成本節約普遍遠低於預期;更扎眼的是,44%的大型企業正在用"上一輪AI尚未兌現的費用節省"來論證下一輪AI投資的合理性。貝恩把這種操作定性為"一個存在結構性漏洞的循環賭注"。
落到具體公司,數字則更加誇張,據打車巨頭Uber透露,僅2026年前4個月,公司就耗盡了全年的Token預算;而美國知名網絡服務商Salesforce則表示,今年支付給Anthropic的費用將達到約3億美元。
美國的科技巨頭同樣開始捂錢包:亞馬遜叫停了內部的AI使用排行榜,原因是員工為了刷排名刻意執行不必要的任務、推高Token消耗;微軟則計劃在6月末前,逐步停用多個關鍵產品部門員工的Claude Code訂閱。
當超級大公司亞馬遜都開始心疼Token的時候,成本就不再是創業公司才需要操心的問題了。
而美國企業花錢最多的,恰好是費用最貴的兩家AI大模型公司。
Ramp自家的AI指數顯示,Anthropic和OpenAI在美國企業中的付費採用率分別達到34.4%和32.3%,Anthropic還是首次反超OpenAI。這兩家的旗艦模型定價長期站在全行業最高一檔,企業的AI支出大頭,幾乎就是給這兩家的賬單。
Ramp的首席經濟學家阿拉·卡拉齊安那番"成本紀律"的判斷,說的正是這個處境:錢已經花出去了,回報遲遲沒到,於是,各個美國公司的財務部門開始挨個審視每一行AI開支。
對於企業而言,省錢的路無非兩條,要麼少用,要麼換便宜的。亞馬遜和微軟選了前者。趨勢榜上的那批公司,選了後者。

美國知名AI模型OpenAI和Anthropic。圖自社媒
當價格降到1/4,人們開始“用腳投票”
就在美國企業被高額AI賬單困擾時,DeepSeek在今年5月剛好遞上了一個很難拒絕的報價。
5月22日,DeepSeek宣布旗艦模型V4-Pro的API價格永久下調至原價的四分之一:限時優惠結束後,每百萬Tokens輸入價格低至0.025元(緩存命中)、3元(緩存未命中),輸出6元,再次刷新全球主流大模型的底價紀錄。
根據第三方測算,在相同任務複雜度下,V4-Pro的平均調用成本約為GPT-5.5的十分之一,約為Claude Opus 4.7的十一分之一。
低價對DeepSeek來說不是新策略。早在2024年V2降價引發國內大模型價格戰時,創始人梁文鋒就在接受採訪時講過定價原則:核算成本後定價,"不貼錢,也不賺取暴利",降價的底氣來自下一代模型結構帶來的成本下降,"API和AI都應該是普惠的、人人用得起的東西"。
如果說當時這番話聽起來像一家中國創業公司的自我要求,那麼兩年後,DeepSeek的普惠定價開始在美國公司的對公賬戶落地。
而在企業掏錢之前,開發者群體已經對DeepSeek投下了自己的信任票。
全球模型聚合平台OpenRouter的數據顯示,5月18日至24日當周,DeepSeek V4-Flash以3.43萬億Tokens的周調用量登頂全球第一,DeepSeek旗下模型周調用總量達到5.74萬億Tokens,超過Anthropic與谷歌,連續兩周位居全球廠商第一。
同期,整個中國模型陣營的周調用量達到9.22萬億Tokens,連續四周壓過美國模型的4.93萬億Tokens。OpenRouter的用戶以海外開發者為主,中國開發者只占約6%,這份榜單上的每一筆調用,基本都來自海外開發者的真實選擇。
開發者用腳投票在先,企業用預算跟進在後。對企業軟件來說,這條"開發者先用、公司後買"的路徑再經典不過,過去二十年,AWS、GitHub、Slack都是這麼走進美國企業的,只不過這一次,走這條路的是一家中國的模型公司。
中國模型進入美國公司,DeepSeek不是第一個,也不是唯一一個。
早在2025年底,Airbnb的CEO布萊恩·切斯基就公開說,公司"大量依賴阿里巴巴的Qwen模型,它又好又快又便宜",OpenAI的模型反而"在生產環境裡用得不多",這番話今年還招來了美國眾議院的問詢。
今年3月,估值近300億美元的AI編程工具Cursor推出新模型Composer 2,發佈24小時內就被開發者扒出底座是月之暗面的Kimi K2.5,聯合創始人阿曼·桑格(Aman Sanger)事後承認,"一開始沒在博客裡說明基於Kimi,是個失誤"。
這些公司用中國模型的方式,和DeepSeek這一次不一樣。Cursor用的是Kimi的開源權重做二次訓練,Airbnb的Qwen也是自己部署,切斯基反複強調"我們沒有向任何中國公司提供數據"。它們調用的是中國開源模型的能力,錢并沒有進中國公司的賬。
而Ramp這次記錄到的是另一回事,美國公司在直接給DeepSeek付費,數據也直接經DeepSeek進出。從"拿開源權重自己跑"到"付錢直連託管",這才是今年6月這張榜單真正的新意,也正是卡拉齊安特意點明"這不只是自部署"的原因。
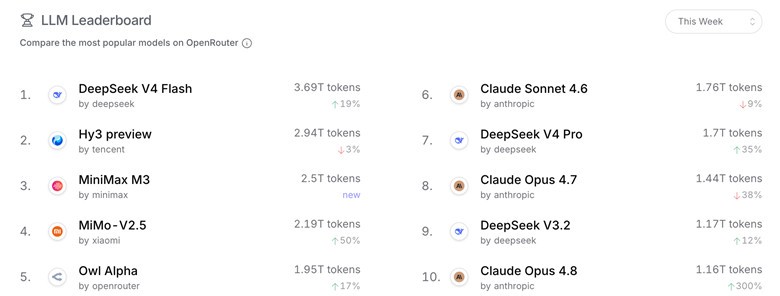
OpenRouter“本周”模型調用榜,DeepSeek V4 Flash 位列第一;前十里還有騰訊、MiniMax、小米等多家中國模型。圖自OpenRouter官網數據截圖
美企高昂的AI預算壓力,該如何化解?
對於DeepSeek衝上美國企業訂閱榜的結論,Ramp的首席經濟學家阿拉·卡拉齊安在報告裡補了一段:"我不會高估這個趨勢的持久性。對企業來說,直接接入DeepSeek存在真實的競爭與安全顧慮。"
美國企業直接把數據發給一家中國公司的服務器,合規部門不可能沒有意見。這層顧慮是真實的,也未必是DeepSeek短期能解決的。
但卡拉齊安這段話的後半句,分量不比前半句輕:"美國模型公司無論如何都應該注意到這種競爭壓力,用更便宜的模型,或者用智能路由,幫企業管住不斷失控的AI支出。"
簡單翻譯一下:即便美國企業明天就因為安全顧慮集體退掉DeepSeek,逼它們走到這一步的成本壓力也不會消失,OpenAI和Anthropic的定價體系照樣要回答這道題。
何況趨勢榜上的信號不只DeepSeek一個。同月上榜的還有Fireworks AI、fal、DeepInfra這批開源模型推理平台,美國企業在整體性地轉向開源和低成本方案,DeepSeek只是這場遷徙裡最顯眼、也最讓人意外的那個目的地。
便宜也可能是另一段麻煩的開始。進入Agent時代,一個任務要反複調用模型、自己寫代碼、自己跑測試、自己糾錯,吞掉的Token是過去一句一答的幾倍甚至幾十倍。
測算顯示,當Agent的滲透率爬到8%,它消耗的Token就追平了聊天機器人,往後還有5倍以上的空間。單價降到四分之一,調用量翻上十倍,賬單只會更厚。DeepSeek的低價把更多公司請進了門,也把它們更深地推進了這場停不下來的消耗。
一年半前,DeepSeek-R1發佈引爆全球,那個"約560萬美元訓練成本"的故事讓矽穀集體恐慌,英偉達單日蒸發近6000億美元市值。
儘管當時DeepSeek對股市的恐慌一周就能平息,但如今愈發壓力山大的AI預算壓力,每個月都會準時拷問所有的美國企業。(完)



